
어쩌다 보니, GLUE와 EMR을 공부해야되서, 먼저 정리한다.
지금 회사에서 일하면서도 항상 아쉬운 것은 실물 장비를 장비를 한번 직접 봤으면... 직접 한번 운영해 봤으면...
하는 아쉬움이 있다. 자료는 뭐 이럴때 쓰면 된다. 짱이다 성능 좋다. 탁월하다 뭐 이딴 소리만 적어논 문서나 보고 제품을 제대로 이해하라고 하니..
뭐 아마존 문서라고 다를게 있나.
여튼. 그래도 찾고 또 찾아서 정리를 해본다.
일단
GLUE는 ETL 도구이다.
그리고 EMR도 ETL 도구로 활용할 수 있다.
다시 말하면 GLUE는 ETL을 위해 전용으로 만들어진 서버리스 ETL 툴이고,
EMR은 하둡이나 스파크를 활용하여 ETL도 할 수는 있다. (그럼 ETL말고 뭘 하나 싶지만 그건 모르겠다.)
GLUE나 EMR을 제대로 이해하기 위해서는 빅데이터의 전처리, 후처리를 이해해야한다.
그럼, 우선 빅데이터란 것이 무엇일까?
빅데이터의 정의를 찾아보면 3V, 4V, 5V 어쩌구 하는데,
그냥 모든 데이터들을 말한다. 즉 빅데이터가 나오기 전에 데이터 라는 단어는 특정 정형 데이터로만 한정지었던 것 같다.
그래서 반정형, 비정형에서 활용 가능한 NoSQL이 빅데이터에 좋고 어쩌구 저쩌구 하는거 보면,
RDB에 부합되는 데이터, 이것이 기존의 데이터였다면,
빅데이터는 RDB의 형태가 아닌 데이터들을 비롯해서, 존재하는 모든 데이터를 대상으로 하는 것으로 보인다.
만약 설문조사를 진행을 했고, 성별, 나이, 문항의 답변들 이렇게 3가지로 구성되 있다고 하자.
성별, 나이, 답변들 => 답변의 스키마(구조)이고, 이것이 기존의 데이터의 범주라면,
나이, 성별, 답변들
답변, 나이, 답변, 성별, 답변..
답변들,
영어로 씌여진 나이, 성별, 답변...
와 같이 설문조사 답변이긴 하지만, 답변의 스키마를 충족하지 않는 애들은 기존의 데이터의 범주가 아니라 빅데이터의 범주에 속하는 애들로 보인다. (구조가 엉망인 채로 데이터가 들어온 것을 예로 들고, 그것을 ETL 하는 과정만 봐서 왜 이런식으로 들어오는지는 모르겠으나) 답변 형식이 자유로워서 스키마를 예측할수 없거나 뭐 그런 경우가 있지 않을까 싶다.
여튼,
저렇게 답변들이 온다면, 우리도 먼저 하는 일이 답변의 내용을 정리하는 것을 먼저할 것이라고 생각한다.
예를 들어서, 성별 이란 답변에, 누구는 남 혹은 녀 이렇게 쓸 수도 있고, M 혹은 W 이렇게 쓸수도 있고, Male 혹은 Female, 아니면 LGBT에 따라 뭐 복잡한 성별을 적을 수도 있다. 그러면 추후 분석을 위해서 남 그리고 M, Male 등은 남성으로, 녀와 W, Female 등은 여성으로 나머지 성들은 제 3의 성으로 값을 변경할 것이다.
그리고 나이도 누구는 19살, 누구는 24세, 다른 또 누구는 30대, 이런식으로 적을 수도 있다. 이럴때는 살, 세 이런것들은 다 제거해버리고, 대 로 되어있는것은 중간 값인 35 이렇게 바꿔버릴 수도 있다. 그리고 만약 나이가 999세 혹은 -20세 이런 값이 있을 수도 있다. 나이가 분석에 필수요소라면 이런 답변들은 분석에 포함시키지 말고 미리 버려야한다.
그리고 만약 성별, 나이, 답변 중 하나라도 누락이 되는 자료는 쓰지 않는다고 할 때, 이런 Missing value가 있는 답변들을 미리 버릴 것이다.
이러는 것이.
빅데이터 전처리 이다.
빅데이터를 처리 할 수 있도록 데이터를 정제하는 과정. 값을 형식 표준화 하여 통일 시키고, 잘못된 값(불필요한 값)등을 수정하고, 부족한 값이 있는것 등을 제외시키는 것이다.
이런 것을 데이터프로파일링, 데이터 정제 이라고 하기도 하는 것 같은데, 데이터프로파일링은 전처리보다 조금 더 큰 개념으로 보인다.
그리고, 이를 쉽게 할 수 있도록 지원하는 AWS Glue databrew이다.
이런 과정은 당연히 시간이 많이 걸릴 것이고, 기존의 방식으로 하면 전처리를 위한 코드 작성이 필요했다. 하지만 Glue databrew를 쓰면 GUI를 통해서 쉽고, 그리고 빠르게 데이터 전처리가 가능하다.
다음 글에서 정리해볼 Glue studio가 Glue crawler와 Glue catalog를 활용해서 ETL에 초점에 맞춰있다면,
AWS Gluedatabrew는 전치리와 데이터프로파일에 초점이 맞춰진 서비스이다.
근데!
But!
However!
ETL은 Extrat, Transform, Load의 약자이다. 추출은 그렇다 치고,
Transform => 성별 표시를 남성 여성 제 3의성 이렇게 통일시켜 바꾸는 것을 말한다. 즉, Glue studio에서 할 수 있다는 소리이다.
Load => 가령 예를 들어 설문 대상을 파악하기 위해 나이정보와 성별 정보만 필요해서 두 속성을 추출해서 Load 하는 것은 Glue Studio에서 할 수 있는 것은 당연한 것이고, Databrew도 가능하다.

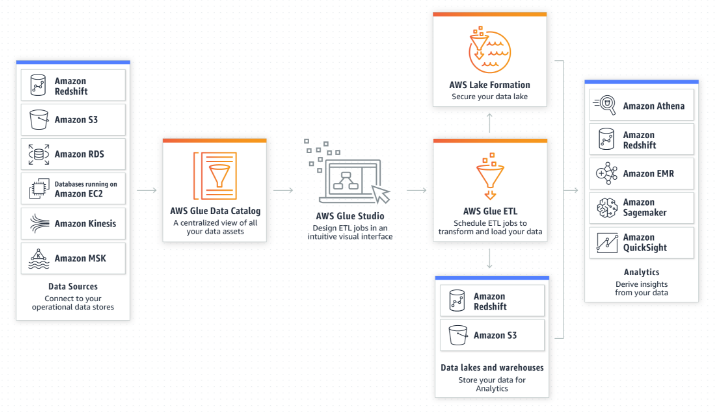
위 다이어그램을 보면, Databrew는 Faster insghts를 위한 것이고, Glue Studio는 Analytics를 위한 것이다.
이것은 보면 Glude stuido가 데이터 전처리까지 어느정도 가능한 것으로 보인다.
그래서 빅데이터 분석을 위해서 Glue Databrew가 필수는 아니지만, Faster insghts를 확보하여 좀 더 빠른 분석(그리고 비용 절감)을 하게 해주는 것이 아닐까 싶다.
'AWS 정리 > AWS 개념 정리' 카테고리의 다른 글
| AWS Athena / Redshift / QuickSight (0) | 2022.01.16 |
|---|---|
| AWS GLUE 와 EMR-EMR/MapReduce/Spark (0) | 2022.01.16 |
| AWS GLUE 와 EMR-/후처리/Glue Studio/Crawler/Data Catalog (0) | 2022.01.16 |
| AWS 정리 1차 - EC2, RDS, S3, CloudFront-1(EC2, S3) (0) | 2022.01.03 |