우선 EMR이란,
하둡 생태계를 구성할 수 있게 클러스터 환경을 지원하는 AWS 서비스이다.
클러스터 구성이기 때문에, 당연히 EC2가 사용된다.
* Glue는 서버리스로 EC2가 사용되지 않고 Lambda가 사용된다.
하둡은 대용량 데이터 분산 처리할 수 있는 오픈소스로, 분산 처리를 위해 MapReduce를 사용하고, 분산 저장을 위해 HDFS를 사용한다. 분산된 데이터를 병렬로 처리하기 때문에 대용량이라도 짧은 시간으로 진행할 수 있다.

MapReduce는 Map() 함수와 Reduce() 함수를 쓴 것을 말한다.
우선 하둡은 input 값을 특정 기준으로 쪼갠다.(Splitting) => Map()
그리고 Map 함수를 이용해서 키/값 쌍으로 변환한다.(Mapping) 위 이미지 같은 경우, 띄어쓰기 단위로 구분하고, 카운트한 값으로 키/값 쌍을 구했다. => Map()
그리고 같은 키들로 모은다. (Shuflling) => Map()
그리고 모아진 값을 합쳐서 더 작은 값들로 만든다.(Reducing) => Reduce()
그리고 모아진 값을 합쳐서 더 작은 값들로 만든다.(Final result) => Reduce()
* 저 그림을 보면서 왜 머지가 아니고 왜 Reduce일까 항상 의문이었는데, Dog, 1 Dog, 1, Dog, 1 ... 이렇게 있는 "값"을 Dog, 5 이렇게 두 개로, 작은 "값"으로 만들어서 Reduce라고 하나보다.
input 값을 보거나 result 값을 보면 비정형 데이터를 처리하는 구조이구나 싶다.
다시 한번 정리하면, MapReduce는 저장소에서 데이터를 읽어오고, 쪼갠 후 Map으로 Key/value 형태로 연관성 있는 데이터 끼리 묶고, 그런 후에, Reduce하여 작은 값들로 만들고 최종 작은 값을 저장소에 저장한다.
여기서 그런 후에, 가 MapReduce의 단점이다. Map 함수가 종료 된 다음에 Reduce 가 수행되는데, 그 이유는 Map 함수의 결과를 중간에 Disk에 쓰고, 쓰인 그 데이터를 읽어와서 Reduce 함수가 수행되는 구조이기 때문이다. 디스크 쓰고 다시 그것을 읽는데서 시간이 많이 소요된다.
그래서 성능이 빠른 In-memory를 사용해 쓰고 읽고 캐싱해서 처리의 성능을 높인 서비스가 Spark 이다. Spark는 Map 함수가 전부 종료되지 않아도 Map 결과를 스트리밍 하는 방식으로 Reduce함수가 진행된다. 이러한 방식과 빠른 In-memory 성능은 실시간에 가까운 처리을 가능하게 한다.
Spark는 HDFS(MapReduce)와 같이 사용될 수도 있고, 별도로 사용될 수도 있고, spark가 다른 제품과 사용될 수도 있고 그렇지만 하둡과 밀접하게 연동된다.
spark가 하둡에 비해 좋아보이지만, 아직 하둡도 사용되는 이유는 가격이지 않을까 싶다. 데이터가 크면 클수록 큰 메모리가 들어가야할텐데, 메모리 비용이 싸진 않다. 그렇다고 작은 메모리로 하게 되면 당연히 성능이 떨어질 수 밖에 없다. 그리고 HDFS랑 연동되고 다른 파일 시스템과 연동이 가능하지만, 이 말은 즉슨 관리 포인트가 늘어난다는 것이다. 하둡을 쓰면 하둡만 알고 하둡만 관리를 하면 되지만, Spark를 사용하게 되면 spark와 사용할 파일시스템, 그리고 연동 관련 이슈 등 신경쓸 것이 늘어난다. 아직은 머신러닝 같은 것에 할 수 있는 것이 제약된다.
정리했던 내용 중 일부 --
Amazon EMR은 대규모 분산 데이터 처리 작업 등이 가능한 클라우드 빅 데이터 플랫폼입니다. EMR은 Spark와 Hadoop 과 같은 오픈소스 분석 프레임워크를 지원합니다. AWS EMR은 EMRFS를 지원하여 S3를 데이터 저장소로 이용할 수 있도록 지원합니다. S3를 사용하기 때문에 대용량 처리에 유리하며, 데이터가 분석에 사용되는 빈도에 따라 S3-IA, S3-Glacier등으로 옮겨 가격 효율적으로 데이터 보관이 가능합니다. 또한, HDFS만 사용하게 된다면, 컴퓨팅과 스토리가 분리되지 않지만, EMRFS를 사용하게 되면 컴퓨팅과 스토리지를 분리할 수 있습니다. 분리를 하게 되면 더욱 가격 효율적이고 확장성을 높일 수 있습니다. 분석 속도를 높이기 위해 EMR cluster(컴퓨팅)만 확장 시킬 수 있고, 분석 작업이 필요하지 않거나 빠른 속도가 필요하지 않을 때, EMR Cluster를 축소 시킬 수 있기 때문입니다. 또한 Autoscaling을 통해 EMR 클러스터의 EC2 인스턴스 수의 조절이 가능합니다. 이때, 스토리지로 사용되는 S3는 확장되거나 축소될 필요가 없습니다. 반대로 S3가 확장되거나 축소되어야 할 필요가 생겨도 EMR 클러스터는 관계가 없습니다. 만약, HDFS만 사용하는 환경이라면, 컴퓨팅과 스토리지가 하나로 묶여 있기 때문에, 컴퓨팅혹은 스토리지 쪽에서 낭비가 일어나거나 낭비를 줄이기 위해 추가 작업이 필요할 수 있습니다.
--
EMR을 설명하고 싶은거지 하둡을 제대로 알고싶은 마음은 없으므로, 대충 여기서 마무리하고...
EMR(하둡, 맵 리듀스) 또한 ETL이라고 하는 글들을 많이 봤는데.. 딱히 이유는 없고 title에 ETL 툴 EMR 뭐 이런..
이게 Extrack 하고 Transform 하고.. Load 했다라. 뭐 map이 extrack하고 transform하고, reduce가 transform하면서 load를 했다 이런건가 싶은데..
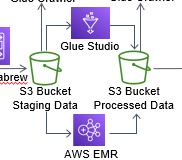
이 구분을 짓고 싶은 이유는 아래와 같은 아키텍처 때문이다.

전처리에서 Glue를 쓴 건 전처리니까 그렇다 치자.
후처리에 Glue를 쓰거나 EMR을 쓰거나 이런 구조가 많다. 실제로 많은지는 모르겠고, 아마존에서 만든 자료들을 보면 거의 저렇다.
앞 글에서 간단히 적었듯이 정형 데이터면 GLUE 로 ETL 작업을, 비정형 데이터면 EMR을 사용하면 된다 이러고 싶은데, 글들을 보면 그게 또 아닌가 싶다.
그리고 하둡도 정형 데이터가 저장된 RDB의 데이터를 가져와서 분석도 가능하다. 마찮가지로 GLUE도 비정형 데이터 분석이 가능하다.
그럼 언제 GLUE를 쓰고, 언제 EMR을 쓸까?
간단한 ETL 작업을 진행하려고 할 때,(별 다른 설정 없이 진행 가능, 반대로 단점이 될수 있음)
분석해야 되는 양이 많지 않을 때,
항상 분석을 하는 것이 아니라 특정 시기에 분석을 하려고 할 때,
이때는 Glue를 사용하는 것이 좋아보인다.
반대로
양이 많을때,
저렴한 가격으로 분석을 하고 싶을 때(서버리스(lambda)는 EC2를 사용하는 것보다 비싸다) => 양이 많아서 분석이 오래 걸리는 것을 서버리스로 돌려버리면 가격이 매우 비싸진다는 얘기다.
데이터 분석을 위해 다양한 설정이 필요할 때(Glue는 서버리스라서 제한된 설정만 제공하지만, EMR은 EC2, EBS, S3를 이용해서 하고싶은대로 하면 된다.)
로 보면 될 것 같다.
+ Spark 기반의 아키텍처를 생각한다면 Glue를 쓰는 것이 맞다.
기존 워크로드가 하이브 기반이거나 스트리밍 기반이면(2019년 기준) Glue 사용이 불가능 => EMR 사용
Glue가 다양한 메모리를 지원하기는 하지만 커스터마이징은 미지원
Glue를 쓰든 EMR을 쓰든 이런 과정을 통해 다시 정립된 데이터는 Processed Data가 된다. 정확한 단어는 아닐 것 같다. consume data라는 글도 봤고, 뭐 여튼. 정제되가 될 대로 되어 이제 사용(소비)하면 되는 데이터가 된 것이다.
'AWS 정리 > AWS 개념 정리' 카테고리의 다른 글
| AWS Athena / Redshift / QuickSight (0) | 2022.01.16 |
|---|---|
| AWS GLUE 와 EMR-/후처리/Glue Studio/Crawler/Data Catalog (0) | 2022.01.16 |
| AWS GLUE 와 EMR-우선 빅데이터/전처리/Glue Databrew (0) | 2022.01.15 |
| AWS 정리 1차 - EC2, RDS, S3, CloudFront-1(EC2, S3) (0) | 2022.01.03 |