이번 글에서는 후처리와 Glue Studio를 정리해보려고 한다.
데이터를 전처리를 했다고 해서 그 데이터를 기반으로 바로 데이터 분석은 불가능하다.
데이터 정제된 데이터들을 분석할 수 있도록 데이터를 정리하는 것이 후처리이다. 후처리가 된 자료를 보고 데이터 분석이 가능해진다.
처리 방법 중 하나가 ETL이다.
ETL은 Extract, Transform, Load의 약자이다.
Extract, 추출이란, 데이터를 골라서 가져오는 것이다.
워낙 많은 데이터들이 있을텐데, 분석을 위해서 그 모든 자료가 필요하지는 않을테니 필요한 속성 데이터만 가져오는 것을 말한다.
Transform, 변환이란, 변환하는 것이다.
앞서 말했듯이 남성 여성 제 3의 성 이렇게 표준화하여 정리하는 것도 있겠지만, 개인정보 보호를 위해 이름을 홍*동 이렇게 바꿔야할 수도 있고, 필요에 따라 홍 길동 이렇게 성과 이름을 분리하여 데이터가 저장되어야할 수도 있다. 이렇게 분석에 사용될 수 있는 형태로 바꾸는 것이다.
Load, 적재란, 추출하고 변환환 데이터를 저장하는 것이다.
나이와 성별만 필요하다면, 변환된 나이만 가지고 테이블을 만든다.
특정 속성 값들을 가지고 테이블을 만든다. RDB 같지 않은가?
ETL은 RDB가 아닌(속성 값들은 가지고 있지만 스키마가 엉망인?) 애를 RDB와 비슷한 형태로 만드는 과정으로 보인다.
(이렇게 ETL된 자료를 Redshift로 보내는데, Redshift는 RDB이니까 RDB로 봐도 될것같기도하고..)
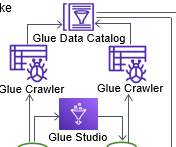
Glue Studio가 이것을 바로 해주는 것이 아니고,
이것을 해주는 것이 Glue Crawler와 Data Catalog이다.
*여기서 Glue Studio와 Glue Databrew의 차이점이 하나 더 찾을 수 있는데, Glue Databrew의 경우 S3나, Redshift, RDS 등 스토리지나 DB를 직접 탐색하여 작업을 한다면, Glue Studio는 Crawler와 Data Catalog의 자료를 가지고 작업을 한다.
Glue Crawler는 스토리지나 DB를 탐색하면서 데이터의 스키마를 제안하고, 관련 데이터를 메타데이터이터로 하여 Data Catalog에 기록한다. 스토리지나 DB의 데이터를 복사해서 저장하는 것이 아니라, 메타데이터를 저장하는 것이기 때문에,
Glue Studio는 Data Catalog를 참조하여 스토리지나 DB의 자료를 ETL한다.
그리고 Glue Studio 또한 GUI로 코드 없이 ETL을 가능하게 해주는 AWS 서비스이다.
ETL 외에 후처리를 위한 방법은 하둡을 사용하는 것이다.
예로 든 것처럼 이름, 나이, 답변 이렇게 있다는 것은 정형 데이터라는 것이다. 정형 데이터 비스무리하다던가.
데이터를 정제 후 나오는 형태가 정형 데이터 혹은 정형 + 반정형(비정형) 데이터 형태라면, ETL하는 것이 좋다고 한다.
만약 정제 후 나오는 형태가 전부 비정형(반정형) 데이터라면 이때는 하둡을 사용하는 것이 좋아 보인다.
비정형 데이터를 예로 들어보면,
"나는 비정형 데이터가 싫다. 나는 모든 것은 기준이 확실하고 그 기준에 부합되는 자료만 있어야한다. 나는 그런 기준이 반드시 필요하다고 생각한다."
뭐 이런 글을 데이터로 보고 분석하는 것이다.
뭐 이런것을 "나는" 이 3번 쓰이고, "기준"이 3번 쓰이고.. 뭐 이런 분석?
다음 정리에서 하둡을 사용할 수 있는 AWS EMR과 하둡에서 사용하는 맵 리듀스, 그리고 GLUE와 EMR에서 쓰이는 Spark도 정리해보겠다.
* 정형 데이터 : RDB 같이 스키마를 지원하는 데이터
* 반정형 데이터 : 스키마가 있긴 하지만 RDB같은 형태는 아님. HTML이나 XML, JSON 같은 형태로 있음. , 로 구분된 데이터 모음 같은 것
* 비정형 데이터 : 텍스트나 이미지, 영상
'AWS 정리 > AWS 개념 정리' 카테고리의 다른 글
| AWS Athena / Redshift / QuickSight (0) | 2022.01.16 |
|---|---|
| AWS GLUE 와 EMR-EMR/MapReduce/Spark (0) | 2022.01.16 |
| AWS GLUE 와 EMR-우선 빅데이터/전처리/Glue Databrew (0) | 2022.01.15 |
| AWS 정리 1차 - EC2, RDS, S3, CloudFront-1(EC2, S3) (0) | 2022.01.03 |